摘要
当使用虚拟现实(VR)来呈现学习内容时,三维图像往往是不够的,需要额外的文本,无论是视觉形式还是听觉形式。这种额外的教学文本可能特别有益,因为有许多视觉刺激和视觉工作记忆过载的风险。通过在视听演示中使用两种渠道来缓解工作记忆,可能会有更多的认知能力可用于投资于相关的学习过程。此外,图像和文本可以同时处理,支持更深入的学习过程。基于模态效应,因此可以假设VR中的视听呈现,与仅视觉呈现相比,可以导致更高的学习成果(回忆,理解和迁移)。在受试者间设计中,我们分析了61名受试者(69%为女性)的虚拟现实情态原则。我们假设,当虚拟现实中的口头信息是通过听觉而不是视觉来提供的,它会带来更高的整体学习效果。对于内在认知负荷,我们假设没有差异,但在视听条件下,外部认知负荷较低,相关认知负荷较高。然而,结果显示出相反的模态效应。单纯视觉组在回忆、理解和迁移方面表现出较高的学习成绩。正如预期的那样,这些条件在内在认知负荷方面没有表现出差异。然而,我们也没有发现外来认知负荷的差异。与我们的假设相反,我们发现,与视听条件相比,视觉条件下的相关认知负荷更高,这可能归因于重复阅读、阅读策略或其他自我调节策略。未来的研究可以侧重于策略的使用或评估相关的过程数据。
介绍
使用虚拟现实(VR)学习正变得越来越流行,并已被用于获取医学、工程和心理学等领域的知识和技能(Radianti等人,2020;吴等人,2020)。虽然VR学习环境(VRLE)可以设计得非常详细和逼真,但在大多数情况下,它们需要额外的口头信息来完整地传达学习材料。因此,在优化学习体验时,探索语言信息在VRLE中以何种形态呈现是必不可少的。使用VRLE学习可以区分非沉浸式VR和沉浸式VR。沉浸感指的是VR应用程序的技术性质,它给人的印象是虚拟世界的一部分,或将其视为真实的(Slater & Sanchez-Vives, 2016)。非沉浸式VR意味着学习者可以在计算机上从外部观看VRLE,从而在VRLE期间继续感知周边的现实世界(Slater & Sanchez-Vives, 2016)。当使用沉浸式VRLE学习时,人们完全被学习材料包围,使用戴在头上的头戴式显示器(hmd)。因此,用户的整个视野被VRLE占据,学习者看不到现实世界(Slater & Sanchez-Vives, 2016;吴等人,2020)。本文主要关注沉浸式VR。就虚拟现实的学习效果而言,研究结果存在异质性。虽然一些研究发现了对学习结果的积极影响,但其他研究显示没有影响甚至是负面影响(Makransky, Borre-Gude等,2019;Merchant et al., 2014;Parong & Mayer, 2020)。为了更好地理解这些不同的发现,有必要了解使用VR学习的挑战。VRLE与传统学习环境的不同之处在于,它为学习者提供了更多的视觉输入。如果有太多的视觉输入,它可能会使学习者过载,这对学习产生负面影响(Howard & Lee, 2020;Parong & Mayer, 2020)。在许多情况下,降低视觉保真度以避免潜在的视觉过载并不是一个解决方案,因为它也会降低沉浸感,这是VRLE的一个重要方面(Mills等人,2016)。此外,如果视觉保真度降低,VRLE的良好动机效应可能会受损(Makransky & Mayer, 2022)。为了避免这种潜在的视觉超载,额外的信息,如额外的口头解释,也不应该以视觉方式呈现,而应该通过不同的感官方式提供。这个想法也被称为模态原则,它已经在经典多媒体环境中得到了证实(Mayer, 2005)。现在问题来了,这是否也适用于虚拟现实。从理论的角度来看,人们会清楚地假设听觉通道的使用可以减少视觉通道的过载,在VRLE中也是如此。然而,当代对虚拟现实中的情态原则的实证研究表明,它不能简单地转移到虚拟现实中。它显示了相反的反向模态效应(Baceviciute et al., 2020)。因此,为了更好地理解VRLE中情态效应的框架,本研究旨在通过对潜在认知过程的更详细关注来研究VRLE中的情态效应。为此,我们以不同的方式测量了学习结果和认知负荷,以研究潜在的认知过程。
理论背景
与传统的二维呈现形式的学习材料相比,VRLE在设计学习材料时具有各种优点和缺点。关于优势,在VR中学习可以是互动的,现实的和实时的(Cobb & Fraser, 2005;Slater & Sanchez-Vives, 2016),让用户感到兴奋和激励(Makransky & Lilleholt, 2018;Parong & Mayer, 2020)。适当设计的VRLE可以使学习者更有动力,体验更多的乐趣,并在学习中投入更多的努力(Makransky, Borre-Gude等人,2019;Parong & Mayer, 2018)。许多研究将沉浸式VRLE与更高的动机联系起来(Makransky, Borre-Gude, et al., 2019;Parong & Mayer, 2018)。这种更高的学习动机可能与增加的投入有关,这被称为相关认知负荷(GCL)。这反过来对学习结果产生积极影响(Makransky & Mayer, 2022;莫雷诺,2006)。研究支持这种动机对学习结果的积极影响(Cerasoli et al., 2014)。
VR的另一个优点是它可以以一种尽可能真实的方式刺激学习者的感官,创造一种沉浸在虚拟环境中的感觉(Slater & Sanchez-Vives, 2016)。尤其是空间过程和运动技能的教学可以极大地受益于沉浸式3D演示和VR中的交互性(Parong & Mayer, 2020;吴等人,2020)。例如,生物或化学过程可以被动画化,而学习者可以从多个角度看待这一过程,并独立地与学习材料互动(Parong & Mayer, 2020;Radianti et al., 2020)。Wu, Yu, and Gu(2020)的meta分析结果表明,科学学习内容特别适合hmd学习。此外,使用头戴式显示器的沉浸式VR学习课程可以支持知识获取和技能学习,并具有长期的学习效果。与静态图像或动画相比,VRLE可以动态地对学习者做出反应,例如,根据学习者在环境中的位置。通过这种方式,当学习者出于兴趣走向某些物体时,隐藏的结构就可以被看到,从而使潜在的三维结构可见。这也为每个学习者创造了不同的形象,每个人都有自己的学习经历。然而,图像往往不足以传达预期的信息,需要额外的文字。例如,在关于生物学的VRLE中,如果没有额外的口头信息,仅仅是图像信息将不足以命名所描述的相应细胞体和结构,也不足以解释它们的功能或相互关系。为了传达这些信息,需要额外的文字。因此,在设计VRLE时,重要的是要考虑这些额外文本信息的呈现方式,以便所有学习者都能接收到他们需要的信息,以充分处理学习材料。
然而,也有缺点。从开发的角度来看,创建沉浸式VR学习环境所需的成本和努力可能非常高(Richards & Taylor, 2015)。从学习者的角度来看,当前的视野必须不断更新,这可能导致学习材料的表示发生时间变化,特别是在详细或复杂的VRLE中。虽然技术进步继续减少这些时间延迟,但视觉和身体感知之间的这种差异可能会给用户带来不适,这不利于学习(Slater & Sanchez-Vives, 2016)。这些缺点主要是技术上的缺点,而不是在学习过程中可能出现的缺点。Radianti及其同事(2020)在对虚拟现实学习研究的元分析中也发现了这样一个技术焦点。他们指出,大多数被分析的研究只关注可用性,而没有考虑学习结果或潜在的认知过程。因此,对这些过程进行实证研究更为重要(Radianti et al., 2020)。那么,学习需要哪些过程?为什么这些过程在VRLE中具有挑战性?VRLE的主要特点是其恒定和多样的视觉印象。虚拟现实中的大量视觉刺激可能会使有限的工作记忆容量超载(Mayer & Moreno, 1998)。这表明VRLE本身的特征可能会损害学习过程。如前所述,与其他学习环境相比,VR的一个显著特点是沉浸感。当模拟被视为真实时,它使用户能够体验存在感,使其更加真实(Fabris等人,2019)。然而,这些功能并非没有对工作记忆造成压力。为了提供这样的体验,需要添加更多的细节和视觉效果。例如,在自然科学研究中,可以显示细胞结构的三维视图和详细图像(Parong & Mayer, 2018)。观察角度和深度可能会有所不同,这与教科书上的图像有很大的不同。然而,高度的现实性必然包含一些不利于实际学习目标,但需要在工作记忆中加工的特征。根据认知负荷理论(CLT),这种额外的功能被称为附加认知负荷(ECL)。因此,VRLE本身会导致ECL增加,这可能会分散对相关学习内容的注意力(Makransky, Borre-Gude等,2019)。
在学习过程中,学习者也需要对自己进行空间定位,以便跟随动态内容。这种永久图像通常伴随着口头信息,例如嵌入在视场中的术语或公式,集成的文本字段或作为注释的覆盖文本。特别是当在VR中除了视觉呈现之外还呈现视觉文本时,由于许多视觉刺激和由此产生的视觉通道过载可能会损害学习性能,学习过程可能更具挑战性。
总的来说,考虑到沉浸式VR学习的优势和劣势,问题是如何设计vrle来抵消视觉过载并有利于学习(Radianti等人,2020;Sattar等人,2019)。从经典的学习环境出发,模态原则可以回答这个问题。
情态原则
根据情态原则,视觉呈现,如图片,应该伴随着口语文本而不是书面文本(Mayer, 2005)。模态原则是多媒体学习认知理论(Cognitive Theory of Multimedia Learning, CTML;Mayer 2005)。与Baddeley的工作记忆模型一起,它描述了多媒体学习中发生的一系列认知过程,特别是当信息仅用于视觉处理与视听处理时所需的认知过程。Baddeley认为,视觉信息和空间信息是分开处理的:视觉信息在视觉空间画板中处理,言语信息在语音回路中处理(Baddeley, 1992)。两个存储系统都有独立的容量。在多媒体演示中,例如在VRLE中,应该使用两个通道,以便信息可以相应地分配到两个通道,以避免认知过载。因此,在VR中,除了视觉环境之外,伴随的文字也应该以听觉的方式呈现。当视觉信息在视觉空间画板上进行加工时,伴随的听觉解释可以在语音回路中以独立的能力进行加工。如果文本以视觉方式呈现,则该信息也将是视觉的,并且必须以视觉方式处理。在这个阅读过程之后,视觉文本被转换成音位信息,这些音位信息可以在音位循环中进行处理。然而,学习者首先需要将他们的视觉注意力分散到两个视觉信息源上,这样只会使他们的视觉记忆资源紧张。使用听觉文本可以避免这种注意力分散效应,因为学习者可以同时将注意力集中在视觉输入和听觉呈现的文本上(Rummer et al., 2010)。因此,当工作记忆中同时存在视觉和语言信息时,学习者可以更容易地连接和整合它们,从而促进理解和迁移表现。
在传统的多媒体学习环境中,模态原则对学习结果的积极影响已经得到了大量研究的支持(Ginns, 2005;Harskamp et al., 2007;莫雷诺,2006)。然而,也有研究表明,模态原则对学习结果没有影响,甚至有负面影响(Inan et al., 2015;Tabbers & van der Spoel, 2011)。因此,许多研究观察到一种反向模态效应,即只使用视觉呈现的学习者比使用视听呈现的学习者表现出更好的学习表现(Crooks et al., 2012;Inan et al., 2015;Oberfoell & Correia, 2016)。例如,当呈现更长或更复杂的文本时,或者当学习环境是自定节奏时,模态效应可以逆转。为什么模态效应可以在VRLE中逆转,以及它受到哪些边界条件的约束,将在后面的章节中更详细地解释。
到目前为止的讨论表明,在设计学习环境时,考虑资源和能力约束是很重要的。对于CLT,同样的有限工作记忆假设适用于CTML,可以用来解释不同模态的加工。根据注意力分裂效应,模态效应与ECL有关,因为学习者必须将注意力分散到两个互补信息的刺激上(Youssef-Shalala et al., 2014)。br
虚拟现实中的情态原则
从理论上讲,沉浸式VRLE的情态效应应该特别突出。在强烈的视觉刺激上添加更多的视觉文本可能会使视觉通道过载。然而,迄今为止有限的经验证据表明,在VRLE中只有反向模态效应。Baceviciute及其同事(2020)最近的一项研究中,78名学生在VR中接受了关于癌症的学习课程,他们操纵了演示方式。在第一种纯视觉条件下,文本在语义上嵌入在虚拟书中。在第二种纯视觉条件下,文本覆盖在透明背景下的VR上,在视听条件下,文本以听觉方式呈现。他们发现了一种相反的模态效应,即两种视觉条件下的受试者在回忆方面的表现明显好于视听条件下的受试者。相比之下,在迁移绩效方面,不同条件之间没有发现显著差异。这项单一研究的结果表明,在虚拟现实中学习可能受益于反向模态效应。为了解释VR中的反向模态效应,Baceviciute及其同事(2020)提出了Colavita视觉优势效应。根据这一效应,当多感官刺激同时呈现时,视觉刺激在同时呈现时优于听觉刺激(Colavita, 1974)。这种视觉优势甚至可能在注意力过程出现之前就出现在感觉层面(Sinnett et al., 2007)。然而,这种影响主要是在视听辨别任务中研究的,而不是在学习环境中研究的。然而,为了更好地理解这些结果,我们应该考虑模态效应的边界条件。模态效应的有效性可能会受到某些学习条件的限制或逆转,例如,如果文本很长或学习材料非常复杂(Leahy & Sweller, 2016)。尤其是对于较长、较复杂的文本,文本阅读过程中自我调节的可能性可以弥补加工劣势(k
在Baceviciute和同事(2020)的研究中,学习者能够自己决定何时进入下一个学习内容。当学习环境是学习者节奏而不是系统节奏时,也会出现反向模态效应(Ginns, 2005)。因此,如果学习者有足够的时间来处理视觉学习材料,视觉过载可以通过按照自己的节奏重新浏览相关信息或使用文本处理策略来补偿(Tabbers & de Koeijer, 2010)。由于Baceviciute及其同事(2020)的研究没有记录参与者在阅读视觉文本时花费的时间与不可重复的听觉条件相比,因此阅读中的重复效应也可能是视觉条件比听觉条件取得更好结果的原因。
另一个原因可能是,与纯视觉呈现的永久性文本不同,听觉呈现的学习内容不能重复,也不可能在阅读时在元素之间来回跳跃,而永久性文本就是这种情况(Seufert et al., 2009)。然而,文本呈现中的这些可能性可以促进多媒体学习环境中的重要认知过程(Inan et al., 2015)。
此外,Baceviciute和同事(2020)的学习材料是相当静态的,因此VRLE的优势和可能的附加价值可能没有得到充分利用。学习者被要求尽可能坐着不动,限制他们的身体运动,这使得学习者和VRLE之间的动态内容非常有限,因为学习者看到的图像是静态的,更像是动画。如果这种限制导致学习者在视觉通道中没有经历过载,那么使用两种通道作为模态效应就不会产生促进作用。
此外,图像的视觉文本没有整合到学习环境中,而是静态地固定在学习者的视野中,要么以覆盖的形式,要么以书的形式。同时,学习材料不需要文本和图像之间的联系。如果不需要连接来理解学习材料,那么学习者就不必将注意力分散在不同的视觉来源之间,因此就没有注意力分散效应,因此学习材料的听觉呈现可以被认为比视觉呈现更好。
此外,Baceviciute和同事(2020)只分析了回忆和迁移。为了更仔细地研究VRLE中的模态效应,最好看看理解,根据布鲁姆的分类法,理解位于回忆和转移之间。Baceviciute及其同事(2020)也通过单项问卷和脑电图测量了不同VR学习模式下的认知负荷。视觉条件下受试者的内在认知负荷(ICL)显著低于视听条件下受试者。虽然两种条件之间的元素交互作用没有差异,但在主观ICL评分中,被试认为听觉条件比视觉条件更容易。作者将这种差异归因于听觉文本的波动性,因此学习者不能积极地将他们的认知能力投入到选择和组织过程中。至少没有视觉条件下那么多,在视觉条件下,学习者可以重复文本以整合句子之间的信息。然而,他们发现在这些条件下ECL没有差异。此外,对GCL进行额外的研究,以确定文本条件是否实际上在关联过程中投入了更多的认知能力,这将是有益的。
目录
摘要 介绍 理论背景 情态原则 虚拟现实中的情态原则 本研究 方法 材料和仪器 学习成果 结果 对学习成果的影响 讨论 优势与局限 结论 参考文献 致谢 作者信息 道德声明 搜索 导航 #####本研究
本研究探讨了额外教学文本的形式(纯视觉与视听)对高水平英语学习者学习成果和认知负荷的影响。此外,我们希望更详细地研究认知学习过程,这就是为什么我们以区分的方式测量学习结果和认知负荷。从所提出的理论可以看出,在经典学习环境中,模态效应得到了很好的支持。基于此,从理论上讲,由于视觉保真度高,在VRLE中,模态效果应该更加明显。然而,目前也有一项单一的实证研究显示了VRLE的反向模态效应。因此,在VRLE中存在模态效应的理论论证和反对模态效应的实证论证。为了解决这一困境并得出明确的假设,我们在上半部分解释了为什么我们认为在Baceviciute及其同事(2020)之前的研究中,由于其边界条件,VRLE中的模态效应发生了逆转。因此,我们试图在研究中考虑到这些因素。与Baceviciute及其同事(2020)的研究相反,我们将文本长度显著缩短,以适应两种情况下的工作记忆容量。
我们还特别小心地确保视觉文本与VRLE相结合。视觉文本被附加到相应的视觉元素上,并根据学习者的位置动态调整其旋转,从而可以从VRLE中的任何位置读取文本,同时可以自由移动并查看VRLE中的相关元素。在视觉条件下,如果学习者想要连接文本和图像,他们必须在文本和图像之间交替关注。在视听条件下,学习者不必分散注意力同时加工学习材料并将其连接到工作记忆中,这有利于模态效应。我们还决定使VRLE更精简,然而,我们测量了两种情况下的任务执行时间。这使我们能够控制一个条件在VRLE中是否学得明显更长,这可能会影响模态效应,以及学习结果的可能差异是否与学习花费的时间有关。Baceviciute和同事(2020)将学习结果区分为回忆和迁移,而我们更精确地区分了学习结果,并记录了理解。由于我们在VRLE研究中尽可能地坚持了模态效应的边界条件,我们严格地从经典学习环境中建立的模态效应的多媒体学习理论中推导出我们的假设。然而,为了在结果中反映可能的反向模态效应,我们将使用贝叶斯独立样本t检验对以下假设进行额外评估。
我们的第一个研究问题是VRLE的不同模式是否对学习结果有影响。试图调查VR中认知学习过程的研究通常将学习结果作为一个一般因素来衡量,而不是区分衡量(Makransky, Borre-Gude等,2019;Parong & Mayer, 2018)。这可能被认为是有问题的,因为以不同的方式呈现学习材料可能会影响加工的深度。通过使用这两个通道,工作记忆得到缓解,这有助于提高回忆能力。当涉及到理解和迁移性能时,这种缓解应该更有益(Seufert et al., 2009)。如果在工作记忆中有更多的容量,由于视听呈现,那么多个元素可以同时处理,而学习者不必将注意力分散到不同的视觉来源。这使得学习者能够连接甚至整合学习材料,这对于理解和迁移过程至关重要(Seufert et al., 2009;梅耶,1999)。然而,VRLE中的模态效应是否也适用于不同的处理水平,需要更仔细地研究。因此,在本研究中,我们根据Bloom的分类将学习成果分为回忆、理解和迁移(Bloom, 1956)。
本研究基于已有的多媒体学习理论,为Radianti等(2020)在meta分析中提出的VRLE学习成果及其认知过程的实证研究做出了贡献。根据所提出的理论,我们假设在VR中学习材料的视听呈现会比纯视觉呈现带来更高的回忆(H1)、理解(H2)和迁移分数(H3)。
我们的第二个研究问题是不同的VRLE模式是否对认知负荷有影响。根据最初版本的CLT,有三个主要的认知负荷来源可以增强或阻碍学习(Sweller, 2005)。在我们的研究中,当涉及到教学设计的不同方面的评估时,这种区分仍然是有效的(Klepsch & Seufert, 2020)。因此,为了更好地了解潜在的过程,以一种不同的方式测量认知负荷是很重要的。近期关于VRLE认知负荷的研究也表明了区分认知负荷的重要性(Andersen & Makransky, 2020;Parong & Mayer, 2020)。此外,Klepsch和Seufert(2020)支持在多媒体学习材料设计的研究中,建议对认知负荷进行差异化记录,以便能够更清楚地了解学习结果的潜在过程以及所使用的多媒体设计原则,并能够相应地确定有利于学习的设计选项(Klepsch和Seufert, 2020)。三种负载类型中的第一种是ICL。这是由于学习材料的复杂性或艰难性造成的。学习材料的各个元素或多或少是相互关联的。学习材料中元素之间高度的相互作用或依赖关系对学习者的工作记忆提出了更高的要求,而不是相互关联较少或根本不相互关联的元素。客观地说,ICL不受研究设计的影响(Schrader & Bastiaens, 2012),由于两种情况下都呈现相同的VR学习内容,我们预计视听和纯视觉条件下的ICL不会有任何差异。
特别是在具有强烈视觉成分的沉浸式VRLE中,使用模态原则可以通过减少视觉通道上的负载来提供缓解(Low & Sweller, 2005)。从理论上讲,这种缓解最小化了ECL,并允许学习者将他或她的认知能力投入到相关处理中,这有利于学习(Harskamp et al., 2007)。
然而,在不同治疗方式的VRLE中,尚未发现ECL的经验差异。虽然VR中的一般ECL可能很高,但缺乏缓解的一种解释可能是,文本作为一种模态比瞬态音轨更稳定。这可以使阅读时更容易来回跳跃,因为跳过的文本段落可以很容易地重新阅读(Seufert et al., 2009)。有了音轨,学习者就不能再听错过的课文,也不能使用阅读策略。然而,由于视听呈现减轻了视觉通道并额外使用了听觉通道,因此可以防止工作记忆中可能出现的瓶颈,这表明ECL的减少。从理论上推导,我们期望使用多种模式学习的ECL比仅使用一种模式学习的ECL要低。因此,当信息被分配到两个渠道时,由于较低的ECL (Low & Sweller, 2005),学习者应该有更多的工作记忆容量,然后可以将其投资于GCL (Sweller等人,1998)。
基于所提出的理论假设,我们假设在ICL (H4)方面,不同条件之间不会有显著差异,但视听条件下受试者的ECL会低于纯视觉条件下受试者(H5)。视听条件下被试的GCL也有望高于单纯视觉条件下的被试(H6)。
在处理学习内容时,学习者是否有足够的工作记忆容量来促进相关过程(Kalyuga, 2007;Low & Sweller, 2005)。这可能更适用于工作记忆容量高而不是低的个体(Kozan等人,2015)。相比之下,研究发现,工作记忆容量低而不是高的个体从模态原则中获益更多(Seufert et al., 2009)。因此,除了学习材料的设计外,学习者的动机(Seli et al., 2016)、先验知识(Zambrano et al., 2019)或工作记忆容量(Seufert et al., 2009)等特征也可能影响学习结果,并将作为控制变量进行评估。
方法
先验分析
为了估计必要的样本量,我们进行了先验的功率分析。一项关于学习结果的模态原则研究的荟萃分析报告,中位效应量d = 0.72 (95% CI: [0.52, 0.92];Ginns, 2005)。由于此荟萃分析涉及经典多媒体设置,而不是VR研究,因此我们使用d = 0.52的保守置信区间作为效应大小。对于这个效应量,alpha = 0.05, power = 0.95,预计所需的总样本量约为N = 52 (Faul et al., 2009;G*电源版本3.1.9.2)。
参与者与研究设计
我们收集了61名年龄在19至37岁之间的受试者的数据(M = 23.16;sd = 3.15)。其中女性占多数(N = 42,69%),学生占90% (N = 55)。参与研究的要求是年龄不低于18岁,熟练掌握德语,并通过隐形眼镜或戴眼镜来补偿可能的视力缺陷。实验基于被试间设计,采用被试间因素模式(纯视觉vs视听)。作为依赖测量,我们评估了学习结果(回忆、理解、迁移)和认知负荷(ICL、ECL、GCL)。在前人研究的基础上,纳入相关控制变量:先验知识(Zambrano et al., 2019)、动机(Makransky, Borre-Gude, et al., 2019)、工作记忆容量(Seufert et al., 2009)。
材料和仪器
虚拟现实学习单元
沉浸式VR学习材料(见图1和图2)侧重于人类免疫缺陷病毒(HIV)。学习材料基于cellVIEW工具,在此基础上为本研究开发了VRLE (Le Muzic et al., 2015)。学习阶段平均持续11分钟,包括在导游的带领下参观HIV细胞,其中细胞内的相互关系和过程以3D方式显示。当受试者浸泡在病毒中时,显示病毒的相关外部和内部成分,如蛋白质或衣壳结构,提供360°视图和各种结构的详细图像。在两种情况下,口头和书面文本完全相同。在这个过程中,大分子生物学过程的解释。让我们的VR学习材料从动画或视频中脱颖而出的一个特点是,学习材料会根据学习者的位置做出动态反应。例如,只有当学习者靠近或进入病毒的一个组成部分时,大分子结构才会显现出来。学习者可以在VRLE中自由活动,从四面八方观察细胞膜等结构,也可以从内外观察。根据不同的情况,学习内容的口头解释文本要么以文本形式(仅以视觉形式)呈现,要么由演讲者以听觉形式(视听形式)呈现。口头解释文本的平均长度约为M = 38.94, (SD = 16.02)个单词,由主题专家创建,并为研究从英语翻译成德语。我们确保视觉文本能够顺利地整合到VRLE中。文本的旋转总是动态地适应学习者的位置,从各个方面确保良好的可读性。虽然图1中的静态截图可能看起来有点模糊,但VRLE中的文本清晰可辨。高对比度的轮廓使文本在任何背景下都很突出,以确保可读性。由于学习者位置的动态调整,文本也不会模糊相关结构。视听条件下的音频通过连接在VR头显上的耳机呈现,受试者之间的音量保持一致。当学习者点击相应的说话人图标时,就会播放听觉文本。在这两种情况下,在VRLE中当前相关对象的周围都放置了白色圆圈,以确保两种情况下的学习者始终知道哪个图像属于文本。学习者能够自己决定何时进入下一个学习内容。无法重放内容或返回到以前的内容。VR模拟使用一台Vive Pro HMD (HTC公司,每眼1080 * 1200像素,帧率90 Hz,视场110度)和两个Vive控制器。为了实现全房间范围的跟踪,我们在实验室的天花板上安装了四个Vive基站2.0传感器。他们有可能在跟踪区域内移动(大约为1英里)。2 × 2 m)。无窗的实验室提供了稳定的照明条件,使VR头显的传感器技术不受外界干扰因素的影响。HMD连接在HP Omen电脑上(Intel Core i7-9750 H, NVIDIA GeForce RTX 2080, 16gb SDRAM)。本研究收集的问卷及构念如下。人口统计数据,如年龄、性别、学期,以及参与者以前与VR的接触,也被收集。
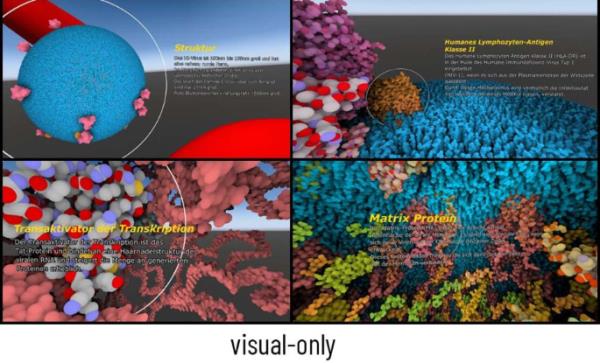
虚拟现实学习环境cellVIEW VR。显示仅可视条件
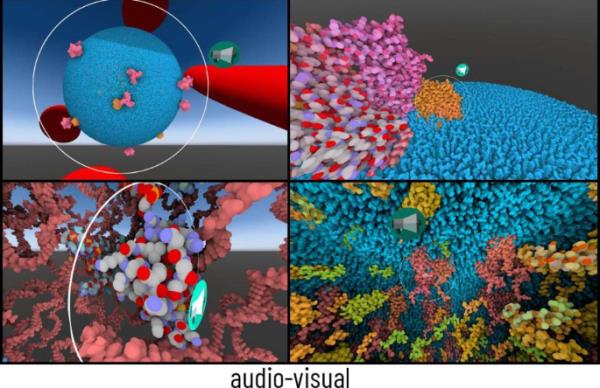
虚拟现实学习环境cellVIEW VR。显示视听状况
先验知识
在研究开始时,对学习者的先验知识进行评估,总共有18个问题(14个开放式问题和4个选择题)。该测试评估了艾滋病毒领域特定知识和基本生化知识。先验知识测试包括18个问题(如“构成RNA的四种核酸是什么?”),可以是开放式的,也可以是选择式的,有四个可能的答案。受试者最高可得28.5分。答错不扣分。用组内相关系数计算组间信度。三位独立的评分者根据先前开发的样本溶液评估受试者的答案(ICC = 0.98, 95% CI: [0.974, 0.990], p < .001)。
认知负荷
学习结束后立即使用差异化认知负荷问卷的三个子量表(ICL、ECL和GCL)评估认知负荷(Klepsch et al., 2017)。该问卷由六个项目组成,7分制(1“绝对不正确”到7“完全正确”),并区分了三种类型的认知负荷。ICL用两个项目来测量(例如,“这个任务非常复杂”)。ECL用三个项目来测量(例如,“这个任务的设计对学习非常不方便”)。GCL也用两个项目来记录(例如,“对于这个任务,我必须集中思考事物的含义。”)。在问卷分析中,量表的信度得分在Cronbach α = 0.80和α = 0.86之间,令人满意(Klepsch et al., 2017)。
学习成果
为了评估学习成果,研究人员根据Bloom(1956)的分类,向受试者提供了13个问题(12个开放问题和一个选择题),这些问题根据回忆、理解和迁移进行了区分。所有问题都是基于之前VR学习材料的内容。有五个回忆题(例如:“HI病毒属于哪个家族?”),四个理解题(例如:“解释逆转录酶如何有助于新病毒的构建。”)和四个转移题(例如:“两个插图中哪一个代表HIV病毒?”)请给出你选择的理由”),总分最高可达20.5分。参与者在回忆上最多得7分,在理解上最多得6分,在转移上最多得7.5分。在适当情况下,这些问题还涉及三维方面,例如在学习成果测试的最后一个例子中,展示了不同病毒的三维图像,或者通过探索三维空间可以从视觉上区分两种衣壳(六聚体和五聚体)的结构。“回忆”的Cronbach’s alpha为α = 0.25,“理解”的α = 0.41,“转移”的α = 0.57。然而,在我们看来,Cronbach’s alpha并不是一个足以表明先验知识或后测的可靠性的度量。这种方法的基本假设是,它评估一个连贯的底层结构。然而,在先验知识和后测中,存在不同的内容面,例如,涉及不同的“章节”。然而,为了确保工具的质量,我们使用了结构效度,即专家开发项目。为了确保可靠性,我们决定采用内部可靠性作为一种可选的合法方法。这个测试是由同样的三个独立的评价者在先验知识测试中评估,使用样本解决方案。组间信度产生非常高的组内相关系数r = 0.98(ICC = 0.983, 95% CI: [0.973, 0.989], p < 0.001)。
动机
当前动机调查问卷(QCM;使用Rheinberg et al., 2001)来测量被试的动机。在李克特7分量表中,从1(完全不同意)到7(完全同意)共使用18个项目,它测量了动机的四个维度。5个项目的“当前兴趣”(例如,“我不需要这样的任务奖励,因为我喜欢它”),4个项目的成功概率(例如,“我相信我能胜任这项任务的难度”),5个项目的失败恐惧(例如,“我觉得做好这项任务很有压力”),以及4个项目的挑战(例如,“这个VR学习课程对我来说是一个真正的挑战”)。“兴趣”子量表的信度为α = 0.83,“成功概率”子量表的信度为α = 0.72,“失败恐惧”子量表的信度为α = 0.91,“挑战”子量表的信度为α = 0.58。为了进一步计算,我们形成了一个总动机分数。总量表的Cronbach 's alpha为α = 0.72。
工作记忆
为了测量工作记忆容量,我们使用了Oberauer及其同事(2000)的数字记忆更新测试。这个数字记忆更新测试,经常用于多媒体学习,特别适合VR学习材料,因为它除了有句法成分外,还有空间成分,这是由于矩阵中数字的排列。此外,它不仅需要学习者存储信息,还需要学习者对数据进行处理。我们开发了一个与原版相同算法的在线版本。参与者面前是一个3 × 3的矩阵,其中每个单元格可以包含一个数字。从三个数字开始,每个数字呈现1300ms。对于每个数字,可以给出几个简单的算术指令,用单元格中的箭头表示(up = + 1;bottom = - 1)。然后依次查询这些单元格的结果。如果在一次尝试中答对75%以上,则单元格数增加1,最多可达9个单元格。如果测试结果低于75%,则重试2次,如果再次失败,测试自动结束。
浸
为了测量沉浸感,我们使用了技术使用量表(Kothgassner et al., 2013)。子量表沉浸感包括四个项目(例如,“在虚拟模拟过程中,我完全忘记了我周围的世界。”),并以7分制进行评分,从1 =“完全不同意”到5 =“完全同意”。Cronbach 's α信度为α = 0.81。
研究过程
首先,所有参与者都被告知了研究的内容,然后被要求仔细阅读并签署受试者信息和知情同意书。随后是一份在线问卷,以评估人口统计数据、先前知识和当前动机。然后,参与者被随机分配到纯视觉组和视听组。简要介绍了控制器的使用和自定进度学习单元的控制。然后,受试者戴上带有集成耳机的VR-HMD开始学习。由于在视觉条件下的受试者理论上可以多次阅读文本,因此花在学习材料上的时间被记录为控制变量。学习单元结束后,立即评估认知负荷。然后,学习者通过回答问卷来评估学习效果、沉浸感和完成评估工作记忆容量的任务。
结果
所有数据分析均使用Statistical Package for the Social Sciences Version 26进行,除使用JASP (JASP Team, 2022)进行贝叶斯独立样本t检验外,所有计算的α-误差设置为α = 0.05。效应大小偏eta平方是根据Cohen(1988)解释的。因此,小效应的极限为0.01,中等效应的极限为0.06,大效应的极限为0.14。计算前检查残差正态分布和方差齐性对ANCOVA计算的要求。检验各协变量回归斜率的齐性。我们还检查了协变量与因变量的相关性在各组之间没有差异。
Des加密数据和co的影响控制变量
描述性统计数据采用t检验进行分析,结果显示年龄(p = 0.64)、先验知识(p = 0.47)、工作记忆容量(p = 0.63)、动机(p = 0.54)、先前接触VR (p = 0.52)、沉浸感(p = 0.22)和在VR学习过程中花费的时间(p = 0.22)在不同条件之间没有差异。χ 2检验未发现不同情况下的性别差异(χ 2 (1, N = 61) = 0.13, p = 0.79)。每种情况下所有控制变量的描述性数据见表1。
为了确定潜在的协变量,我们分析了每个协变量与每个因变量的相关性。相关分析揭示了以下变量的相关协变量:动机(r =。召回率为35,p = .01),先验知识(r =。61, p < .001),理解和动机(r =。23, p = .047)和先验知识(r =。395, p = .002)。
关于ECL,我们发现与浸没相关(r =−)。44, p < 0.001)。对于GCL,与动机显著相关(r =。42, p < .001)和浸泡(r =。40, p = .03)。在接下来的分析中,对控制变量的影响进行了控制。学习成果与认知负荷的描述性统计和ANCOVA结果见表2。
ICL =内在认知负荷;外部认知负荷;关联认知负荷。
下载原文档:https://link.springer.com/content/pdf/10.1007/s11251-022-09611-7.pdf为您推荐:
- 新婚的丈夫为妻子在岛上高尔夫球车上的死亡负责 2024-05-11
- 新的儿童肥胖指南引发了人们对饮食失调风险的担忧 2024-05-11
- 布鲁斯·科特里尔-全世界都在关注着新西兰——但它看到的并不是一幅美好的画面 2024-05-11
- 悉尼母亲在布里斯班水泥墙后与尸体相连,DNA扭曲 2024-05-11
- 已故的斯蒂芬·“推奇”老板在Gap x布鲁克林马戏团的新广告中摆姿势 2024-05-11
- 工会称,阿斯达计划“解雇并重新雇用”7000名工人 2024-05-11


